The BigData hype has largely passed the IBM i by. There are several obvious reasons for this. Firstly, IBM i is not the natural platform of choice for connecting multiple data-generating IoT devices. Secondly, the term BigData is traditionally applied to the processing of unstructured data, whereas IBM i is more of a structured data processing engine.
Strictly speaking, however, the term BigData simply refers to data sets, structured or unstructured, that are too large or complex to be dealt with by traditional data-processing application software. Purists may debate this, of course, but it is clear that large, structured data sets on the IBM i platform present a processing challenge similar in many ways to those addressed by high-throughput computing or MapReduce architectures.
Let’s consider an example of a simplified daily commercial transaction processing batch. It involves two tables, TRANSACT and ACCOUNTS, the former potentially including millions of rows of data accumulated during the current business day. Each transaction must be processed, with the value of the transaction used to update the related account balance. The algorithm for processing a single transaction can be represented by the following sequence of steps:
01 READ TRANSACTION RECORD
02 LOCATE RELATED ACCOUNT RECORD
03 RETRIEVE LAST KNOWN BALANCE
04 CALCULATE UPDATED BALANCE
05 UPDATE ACCOUNT RECORD
06 UPDATE TRANSACTION RECORD MARKING IT “PROCESSED”
The program that is usually written to perform the daily batch processing includes a loop constructed over the above steps:
01 LOOP UNTIL EOF
02 READ TRANSACTION RECORD
03 LOCATE RELATED ACCOUNT RECORD
04 RETRIEVE LAST KNOWN BALANCE
05 CALCULATE UPDATED BALANCE
06 UPDATE ACCOUNT RECORD
07 UPDATE TRANSACTION RECORD MARKING IT “PROCESSED”
08 END-OF-LOOP
The resulting code is obviously extremely inefficient, for it makes use of a single-streamed process to update millions of records, and is thus unable to leverage the multi-processor architecture of the server. Although implementing the above algorithm in SQL may help with performance due to the built-in intelligence of the optimizer, the latter has its limits, and as a result, most financial platforms (on IBM i or servers of other architectures) suffer from long batch runtimes.
Attempts at optimization, e.g. by breaking the processing into multiple parallel streams, yield mixed results. This is due to the lack of consistency, hard-coding of stream controls, and problems with complex code maintenance.
This challenge is not specific to IBM i-based systems, but some advanced features of IBM i can help greatly with its solution. These advanced and in some ways unique features, e.g. ADDLIBE, OVRDBF, OPNQRYF, are often taken for granted by weathered IBM i gurus, but they can form the foundation of an elegant streaming solution for the platform, helping address the long batch runtime problems for practically any existing IBM i ILE/OPM application.
In a nutshell, the idea is simple: a long-running batch processing program is split into several streams, with each stream able to view and, consequently, process only a subset of the TRSANSACTION table rows. Schematically, it can be represented as follows:
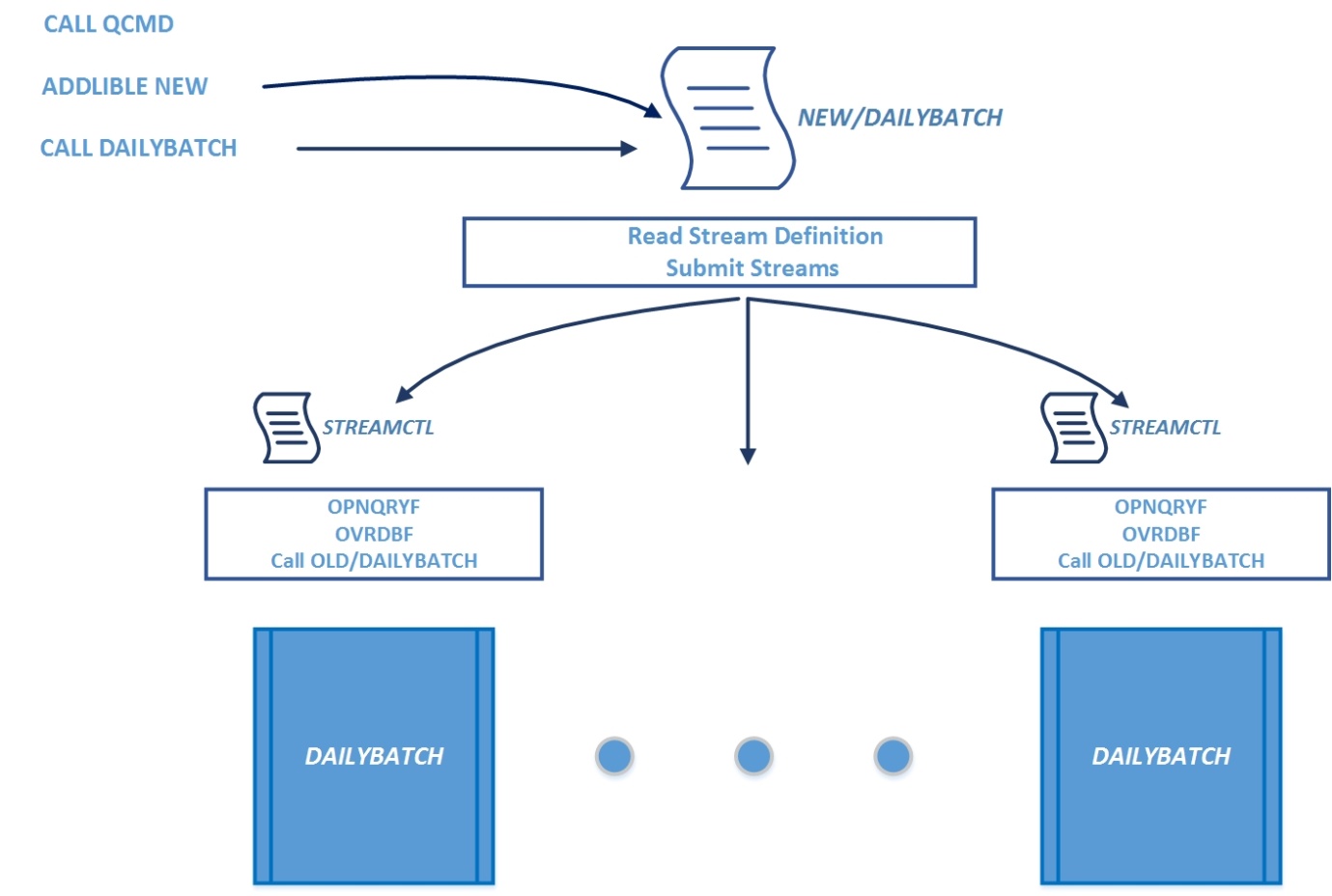 In order to multistream a program with the name DAILYBATCH stored in OLD library, a CL script (program) with the same name is created and added to the library NEW. The script submits multiple stream jobs invoking STREAMCTL program each. The latter issues an OPNQRYF command for the TRANSACT file (or builds a temporary SQL view), selecting a subset of the TRANSACT file records depending on the number of the stream, overrides (OVRDBF) the file in the original DAILYBATCH program to the query file (or the temporary view), and invokes the original DAILYBATCH.
In order to multistream a program with the name DAILYBATCH stored in OLD library, a CL script (program) with the same name is created and added to the library NEW. The script submits multiple stream jobs invoking STREAMCTL program each. The latter issues an OPNQRYF command for the TRANSACT file (or builds a temporary SQL view), selecting a subset of the TRANSACT file records depending on the number of the stream, overrides (OVRDBF) the file in the original DAILYBATCH program to the query file (or the temporary view), and invokes the original DAILYBATCH.
Conceptually, this approach can be very efficient and seems straightforward, but in practice, it’s not so easy to implement, as writing the above framework from scratch would take time and effort, and different batch processes may require different split methods. For example, whilst splitting the TRANSACT file into multiple RRN ranges may be sufficient in some cases, if the DAILYBATCH program were slightly more sophisticated than the example above, say, calculating branch or location subtotals for reporting, this could require a split by branch or location range, rather than by relative record numbers.
However, there is a tool, that can be used to significantly simplify this problematic task.
The tool is called iSTREAM, and as suggested by the name, it helps creating programs based on the pattern of streaming. iSTREAM differs significantly from tools like Hadoop or CouchDB: whilst the latter simply provide frameworks to develop products using MapReduce or Stream Processing, iSTREAM can help configure the existing legacy batch processes to use the multistreaming paradigm – with no additional programming whatsoever.
In order to turn the sample program DAYLYBATCH into a multistreamed batch the following framework commands would have to be executed:
01 DFNSPTPRM PROGRAM(DAILYBATCH)
MASTERFILE((OLD/TRANSACT *FILE *FIRST *N *ALL 10 *ALLIO *CALC (*RRN)))
/* multistreaming definition with stream breakdown by relative record numbers of TRANSACT */02 INZSPTRNG PROGRAM(DAILYBATCH) STREAMS(10)
/* stream definition for 10 streams */03 ISTSSYS/CMPSPTDFN PROGRAM(DAILYBATCH)
/* compilation of the customized programs of the framework */04 STRISTMOD HOTLIB(NEW)
/* entering “iSTREAM” mode of operation in a job */05 CALL DAILYBATCH
/* invocation of the batch */
As a result, multiple streams of DAILYBATCH will be submitted for execution, each for its own range of records from TRANSACT. The main job will be put in WAIT state until the stream processing ends.
Clearly, this is just one basic example of iSTREAM’s capabilities. iSTREAM supports multiple data breakdown methods, e.g. by field/column values of one or multiple files/tables, by field/column values with yet another breakdown for each given range of values, or by automatically balancing numbers of records in each range. The framework can be used with any OPM and ILE program irrespective of the data access interface used, native or SQL.
iSTREAM LP includes seven functional options, of which the multistreaming toolkit is just one. All seven options help optimize existing software or systems being developed, each of them using a flavour of the parallel programming paradigm. Among them are multistreamed versions of CPYF and RMVJRNENT commands, a configurable automated backup using a DR system, and a file sync utility. This has become possible mainly due to the unique IBM i features still missing on other platforms considered contemporary and modern.