There are multiple file copy functions supported by the IBM i platform. They vary in the optional features offered, but regardless of the method used, file copying typically consumes time. The size of the files directly impacts the length of time a user must wait for the copy operation to be completed.
While the save-while-active feature may create the illusion of instant data copying for the initiator, the recipient of the copy still needs to wait for the background process to complete. SAN-based FlashCopy solutions can be seen as a step in the right direction, but they tend to be expensive, can be challenging to configure, and typically operate at the partition level rather than on individual files.
This gap in the fast file copy functionality is not inconsequential, and there is at least one specific use case that simply cries out for it.
Consider a traditional multi-regional ERP or banking system. Nowadays, these systems operate in a 24/7 mode while maintaining daily batch processing tasks, such as interest calculations, balance roll-ups, and inter-division settlements. To illustrate this operational model, we can use the following diagram.
 Throughout the day, the primary system remains open for inquiries and data input. At a predefined time, the user input subsystem is temporarily suspended, and a copy of the key files is created. While the main system proceeds with its daily batch processing, the newly generated night library is utilized to serve divisions of the company operating in different time zones or customers.
Throughout the day, the primary system remains open for inquiries and data input. At a predefined time, the user input subsystem is temporarily suspended, and a copy of the key files is created. While the main system proceeds with its daily batch processing, the newly generated night library is utilized to serve divisions of the company operating in different time zones or customers.
The primary issue here is the downtime necessary to create a copy of files in the production library. For instance, a bank customer attempting to withdraw cash from an ATM during this time might receive a message like, “Your banking system is currently unavailable; please try again later.” The business usually requires a library copy to be completed within a very limited window, ideally within 2 minutes or less.While rebuilding the application to support queries and user input simultaneously during daily batch processing could be a possible solution, application owners often face significant constraints in this regard.
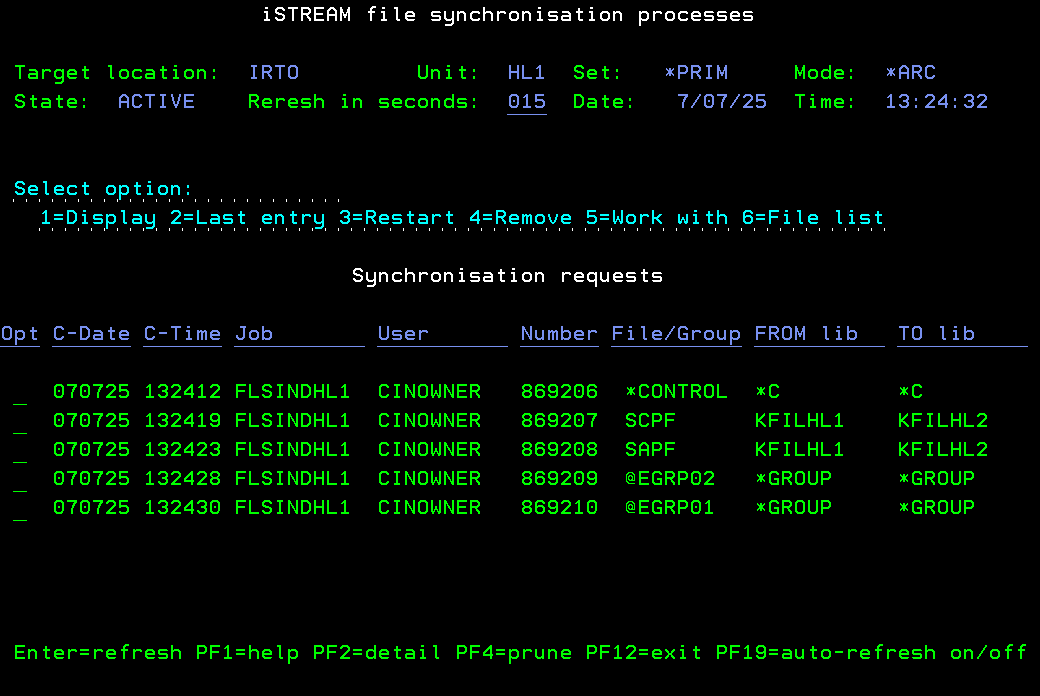
One solution worth considering is the iSYNC File Data Replication feature. It follows a methodology similar to that of traditional HA/DR applications for IBM i, such as MIMIX or Maxava, hence its name. The method used involves creating a copy of the production files in advance, initiating file replication or synchronisation, and by the time of the system swap, the files are effectively replicated. The only remaining task is transitioning the user interfaces from the Day library to the Night library.

While the approach may not appear particularly original, there are several noteworthy distinctions between iSYNC data replication and the replication methods implemented in the enterprise-level platforms mentioned earlier.
First, iSYNC File Data Replication supports multiple algorithms, including those not relying or journals and, therefore, not requiring object journaling. (However, cross-partition replication in iSTREAM can only be implemented for journaled files.)
Second, as a direct result of this, the need to duplicate the production library to match a particular journal entry for future replication is eliminated. Replication can potentially start from the target files containing no records at all. This sets it apart from conventional journal-based High Availability/Disaster Recovery (HA/DR) systems, which often entail intricate and manual setup procedures.
Third, unlike journal-based object replication systems primarily designed for relatively static environments, where file and library deletion and recreation are exceptions, iSYNC excels in managing these tasks treating them as routine operations.
Several other noteworthy features of iSYNC File Data Replication include:
- Transparent restart after replication errors, such as those related to locking.
- Prestart capability saving time and resource at the time the replication process has be be kicked off.
- Availability of APIs (implemented as CL commands) for all primary operations.
- The ability to define target file update strategy.
- Interactive monitoring of replication, supported by APIs
- Support for non-standard file data replication algorithms, such as record archival.
All in all, this feature of iSTREAM is an interesting cost-effective addition to the IBM i fast copy solutions family.